In Brief
Key Takeaways
- Adopt GitOps-Adjacent Workflows: Move away from manual CLI scripts to event-driven, declarative deployments using immutable artifacts to eliminate configuration drift.
- Utilize “Micro-Agents”: Break monolithic scripts into isolated, orchestrated tasks to improve debuggability and handle model timeouts gracefully.
- Optimize Dependencies: Use precision build tools to prune Python libraries, significantly reducing deployment package sizes for faster cold starts.
- GenAI-Specific Telemetry: Standard logging isn’t enough; implement distributed tracing to track reasoning chains, token costs, and model latency.
- Declarative Infrastructure: Centralize environment variables and security guardrails into a single manifest to ensure consistency across AWS accounts.
Why Most AI Agents Never Make it to Production
Most scalable AI agents we’ve seen collapse at the exact same point – not the model itself, but the handoff to platform engineering. A developer builds an autonomous workflow that runs perfectly on their laptop, only to get stuck in weeks of cross-departmental ping-pong. They hit governance roadblocks with strict Service Control Policies (SCPs) , struggle to route traffic through enterprise network restrictions, and face rejection from cloud operations demanding production-grade observability.
This friction doesn’t stop at the initial build. Once a model is coded, engineering teams often face the nightmare of CI/CD for non-deterministic applications. It becomes a struggle to safely evaluate Large Language Model (LLM) outputs, manage prompt versions alongside infrastructure changes, and navigate manual approval gates just to promote a release to production.
The Real Challenge Isn’t Building the Model — It’s What Comes After
For engineers, the challenge of generative AI is rarely about making a model work once. The true complexity is Day 2 operations: How do you industrialize deployment across a multi-account enterprise without losing your mind over security and version control?
The transition from a local Jupyter Notebook to a production-grade platform requires a massive shift in thinking – from ad-hoc scripting to real platform engineering. We built the AI Development Lifecycle (AIDLC) and the Agent Foundation frameworks at AllCloud to address this exact gap. Together, they separate the messy concerns of delivery from the actual runtime.
The Day 2 Deployment Nightmare
Before diving into the solution, let’s look at why this is so painful. Last year, we were reviewing an enterprise deployment where an agent was silently failing in production. The team had no way to trace whether a hallucination was caused by a bad prompt version, a timeout in a downstream API, or an issue with the underlying foundation model. They were flying blind because they treated an LLM workflow like a standard REST API.
Building robust AI workflows demands managing massive Python dependencies, establishing tracing for LLM reasoning chains, and keeping cloud costs from spiraling out of control. By utilizing structured frameworks, you can solve these infrastructure hurdles and let your developers focus strictly on application logic.
AIDLC: Taking back control of the deployment pipeline
The AIDLC acts as the control plane for your deployments. We built this after watching too many agent deployments fail in production because a developer manually tweaked a configuration in the AWS console. It abandons fragile, CLI-driven deployments in favor of an event-driven, declarative architecture.

Why we abandoned CLI-driven deployments
At the core of AIDLC is a “GitOps-adjacent” workflow that completely separates the build process from the deployment process. We moved away from having developers run deployment scripts directly from their machines or CI runners. Instead, we shifted to an architecture driven by immutable artifacts.
The source of truth is now an Amazon S3-based registry where we store versioned, zipped bundles. This creates a hard boundary. Deployment logic is then triggered entirely by object tagging. We use an EventBridge rule that listens for specific tags on that S3 bucket. When a tag is applied, it runs necessary validations and dynamically synthesizes the deployment pipeline based on that specific context. Because the pipeline provisions the infrastructure ephemerally based on the tag, we completely eliminated the configuration drift that used to plague our sandbox and production environments.
Stop scattering environment variables
Instead of hiding variables across the AWS Lambda console, the AIDLC enforces a single source of truth via a declarative deployment manifest.
This file governs behavior without requiring you to touch application code. It explicitly defines your network topology i.e. VPC and Subnet mapping, security guardrails i.e. CMK ARNs for encryption, and your notification systems.
The Agent Foundation: A runtime chassis for scalable AI agents
If the AIDLC handles delivery, the Agent Foundation handles the runtime. It’s a highly opinionated chassis for building Python-based scalable AI agents on AWS. It explicitly tackles the two things that always break in serverless AI: dependencies and observability.
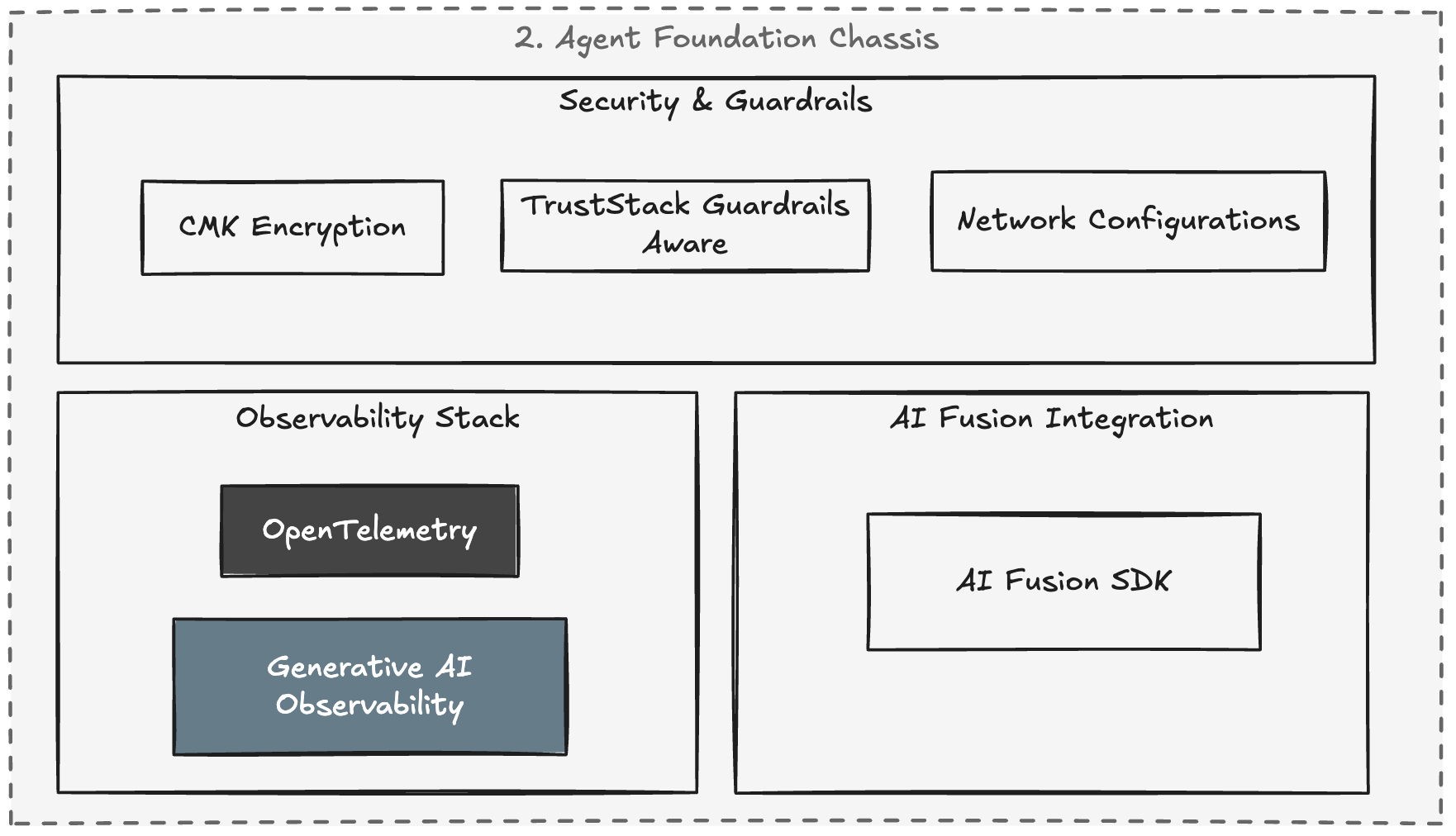
The Python dependency headache (and how we fixed it)
We initially tried standard uv/pip installs in our CI pipelines, but hit Lambda deployment package limits almost immediately with heavy machine learning libraries. To fix this, the Agent Foundation uses a dual dependency strategy.
For local development velocity, engineers use fast package managers like uv to get instant environment setup and linting. But for the actual build artifact, we switch to a precision build system like Pants. By analyzing the import graph and bundling only the exact transitive dependencies required, we routinely reduce deployment packages from over 300MB down to under 50MB, keeping cold starts to a minimum.
You can’t just use standard logging for LLMs
In GenAI, traditional logging is practically useless. You have to track non-deterministic behavior, token consumption, and chain latency. The Agent Foundation embeds a pre-configured telemetry stack based on AWS X-Ray and OpenTelemetry (OTel)
- GenAI Semantic Conventions: We automatically instrument spans with LLM-specific attributes (model IDs, token counts, system prompts.
- Distributed Tracing: Every request gets a unique trace ID across runtime sessions and Lambda processors, giving you a waterfall view of the reasoning chain.
- Automated Dashboarding: Infrastructure-as-code automatically provisions CloudWatch Dashboards. No application goes to production without monitoring latency, traffic, errors, and saturation.
Breaking down the monolith with Micro-Agents
We found that massive, monolithic AI scripts are impossible to debug when things go wrong. The Foundation pushes teams toward a “Micro-Agent” pattern orchestrated natively by AWS Step Functions or AWS AgentCore Runtime
File processing, input validation, and model invocation are completely isolated into distinct steps. When an LLM inevitably times out or fails, the session runtime handles retries and exponential backoff cleanly.
Conclusion: Stop treating GenAI like a web app
Most companies are still treating GenAI deployments like standard web applications. They aren’t. If you don’t standardize your deployment pipeline right now, you’ll end up with a dozen fragile, unmonitorable agents running wild across your AWS accounts, racking up token costs and failing silently.
We built the AIDLC and Agent Foundation because we were tired of debugging the same IAM permissions and dependency conflicts for every new model. By standardizing your control plane, you stop the “works on my machine” excuses. By standardizing the data plane, you ensure every deployment of scalable AI agents is observable, performant, and architecturally sound by default.
The real work of enterprise AI isn’t writing the prompt – it’s building the paved road so your teams can actually ship it.
Ready to take your AI agent deployment from prototype to production?
Contact us to learn how AllCloud can help you build scalable, production-ready AI platforms.