A couple of my recent projects have been using the Amazon SageMaker BlazingText algorithm for text classification problems and I’d like to dive into what it’s about.
The Amazon SageMaker BlazingText algorithm allows AWS customers to tap into highly-optimized implementations of the Word2vec and text classification algorithms. The Word2vec algorithm is useful for many downstream natural language processing (NLP) tasks, such as sentiment analysis, named entity recognition, machine translation, etc. Text classification is an important task for applications that perform web searches, information retrieval, ranking, and document classification.
To understand the BlazingText algorithm, we need to understand Word2Vec:
The foundation of NLP (Natural Languages Processing) is the embedding layer. While dealing with textual data, we need to convert it into numbers before feeding it into any machine learning model, including neural networks. For simplicity, words can be compared to categorical variables. We use one-hot encoding to convert categorical features into numbers. To do so, we create dummy features for each of the categories and populate them with 0s and 1s.
Similarly, if we use one-hot encoding on words in textual data, we will have a dummy feature for each word, which means 10,000 features for a vocabulary of 10,000 words. This is not a feasible embedding approach, as it demands large storage space for the word vectors and thus, reduces model efficiency.
The embedding layer allows us to convert each word into a fixed-length vector of defined size. The resultant vector is a dense one with real values instead of just 0’s and 1’s. The fixed length of word vectors helps us to represent words in a more organized manner along with reduced dimensions.
Embedding word2vec was developed in 2013 by Tomas Mikolov at Google as a response to make the neural-network-based training of the embedding more efficient. Since then, it has become the de-facto standard for developing pre-trained word embedding.
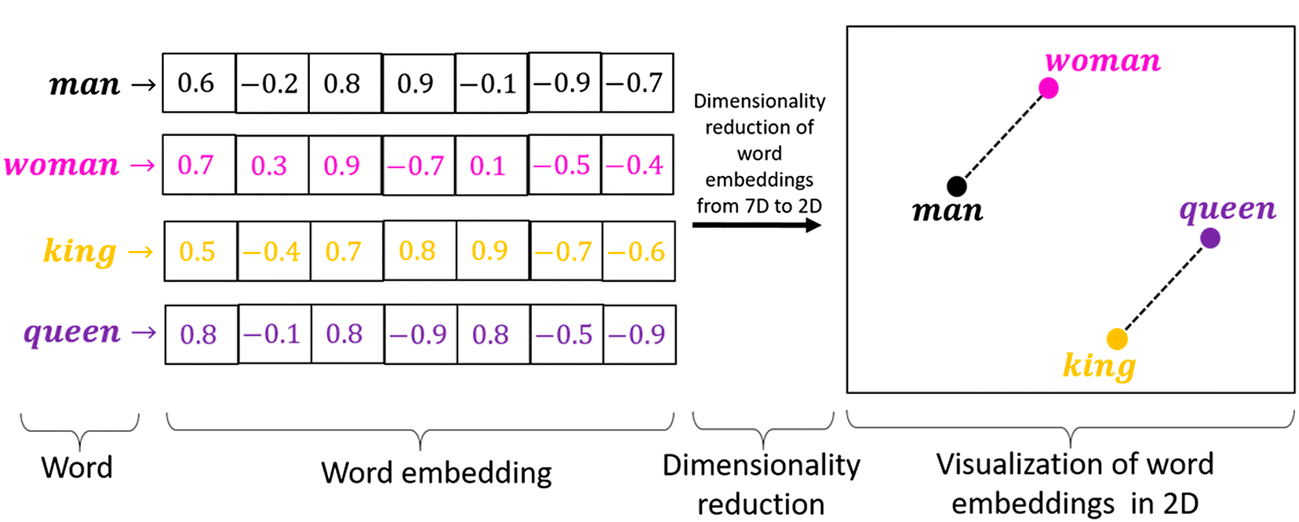
In addition, the work involved analysis of the learned vectors and the exploration of vector math on the representations of words. For example, subtracting the “man-ness” from “King” and adding “women-ness” results in the word “Queen“, capturing the analogy “king is to queen as man is to woman“.
Word2Vec comes in two distinct model architectures: Contextual Bag-Of-Words (CBOW) and Skip-Gram. The objective of CBOW is to predict a word given its context, while skip-gram tries to predict the context given a word. In practice, skip-gram gives better performance but is slower.
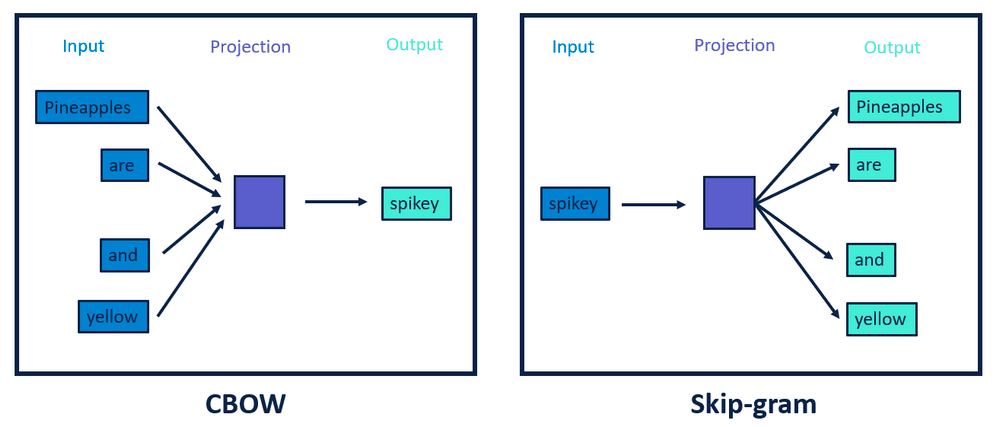
With the BlazingText algorithm, it is possible to scale to large datasets easily. Similar to Word2vec, it provides the Skip-gram and continuous bag-of-words (CBOW) training architectures. BlazingText’s implementation of the supervised multi-class, multi-label text classification algorithm to use GPU acceleration with custom CUDA kernels. It’s also possible to train a model on billions of words in just a few minutes using a multi-core CPU. Lastly, it achieves performance on par with the state-of-the-art deep learning text classification algorithms.
The SageMaker BlazingText algorithms provide the following features:
- Accelerated training Word2Vec on GPUs using highly optimized CUDA kernels.
- Generated meaningful vectors for out-of-vocabulary (OOV) words by representing their vectors as the sum of the character n-gram (sub-word) vectors.
- Leveraging Shared and Distributed Memory for batch_skipgram mode for the Word2Vec algorithm allows for faster training by using Negative Sample Sharing strategy and distributed computation across multiple CPU nodes.
These features allow the BlazingText algorithm to be efficient, fast and the go-to solution for text classification problems.
So if you have textual data and also want to impose algorithms on it in the cloud, reach out to AllCloud’s Data experts for assistance.
See you in my next article