In our last post, we discussed the importance of having an ML strategy. We saw how crucial it was to quickly diagnose what was wrong with a model and to discard possibilities to improve it. The first thing to understand is if your model suffers from High Bias or High Variance. In other words, is it underfitting or overfitting?
Indeed, the respective solutions to these problems are radically different. We say a model is underfitting or suffering from high bias when it’s not performing well on the training set. We say a model is overfitting or suffering from high variance when it’s performing well on the training set but fails to generalize to other data. A picture being worth a thousand words, let’s look at the following case:
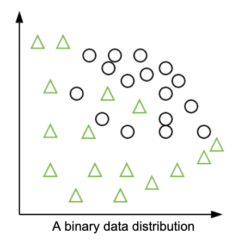
Let’s imagine that our goal here is to create a model that would separate the circles and the triangles. How would you do it? Which geometric line would you draw to separate them?
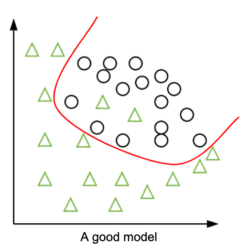
Let’s look at what an underfitting model, an overfitting model and a good model would do.
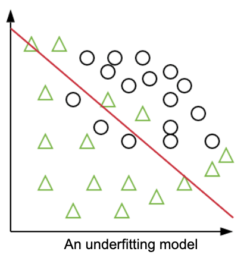
An underfitting model would, for instance, draw a simple red line. As you can see on the picture, it does not separate effectively the data: 3 circles and 5 triangles are wrongly classified. It is not performing well on the training data.
An overfitting model on the other hand would do an amazing job at separating the two classes. Look at the next picture to see the complicated border it would draw. All the circles and triangles are on their own side of the red line.
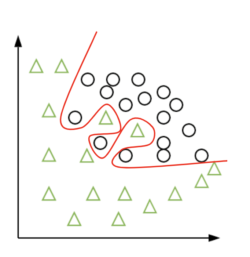
So if it separates so effectively the circles and the triangles, why are we discarding it? Why are we so afraid of this phenomena? Well, if it’s doing so well, it’s because it simply learned the training data “by heart.” This is precisely not the objective of a machine learning model.
Once again, our goal is to learn from training data to be able to use it to generalize to new data. When your model is in production, the data it will face will be new. It won’t come from your training samples. Of course, if your training data was good, the new data will follow the same overall distribution. But it will be different. That’s why the real test of a model is its ability to generalize to new data.
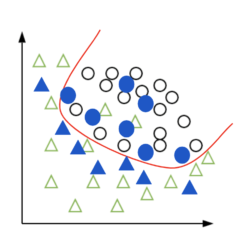
Let’s try to visualize this. The blue data samples are new data points that your model will face in production. It has the same overall distribution as the training data – but clearly the overfitting model is missing some of them. It learned so well the training data, that it’s not able to generalize to new data.
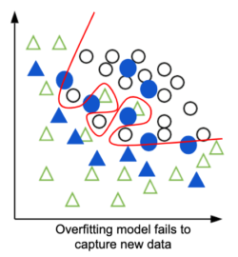
The good model on the other hand, drew a red line that follows the data distribution and is able to generalize well to new data. Granted, two triangles from the training data are on the wrong side but that is not necessarily a problem. They might be “outliers” or diverge slightly from the overall triangles distribution. Once again, the goal is not to fit the training data perfectly but to capture the underlying pattern!
As we mentioned above, both problems of underfitting and overfitting have their own set of solutions. You might have already heard about some of them: add data, increase or reduce regularization, remove data features, etc. How and when to use them will be the subject of our next post, stay tuned!