A decade ago, companies were becoming data-driven to achieve a competitive advantage. These days, being data-driven is table stakes. Most organizations today are working with vast amounts of data from multiple sources. They need the ability to load data quickly and add new data sources without creating bottlenecks. Data Vault was designed to help teams accomplish these goals, and Snowflake maximizes its capabilities like no other data platform that’s currently available.
What is Data Vault?
Data Vault is a modeling methodology for enterprise data warehouses/lakes that blends the best of 3NF and star schema. Because it’s based on agile techniques, it’s highly flexible and easily scalable, making it ideal for high-volume ETL with frequent model changes. Data Vault essentially puts a reference architecture around 3NF, which allows co-locating all of the information from different source systems, and then transforming/conforming the information on the database once landed to make it fit for use all while following a defined pattern.
Data Vault is so game-changing because it dramatically simplifies the ETL process and makes it easy to add new data sources without disrupting the existing schema. And thanks to its built-in audit ability, Data Vault simplifies compliance.
How Snowflake Maximizes Data Vault’s Capabilities
The best way to understand how Snowflake turbocharges Data Vault is to look at the various layers involved in Data Vault. We have the source systems, a staging area, raw vault and business vault, and our access layer with star schemas and data marts, etc.
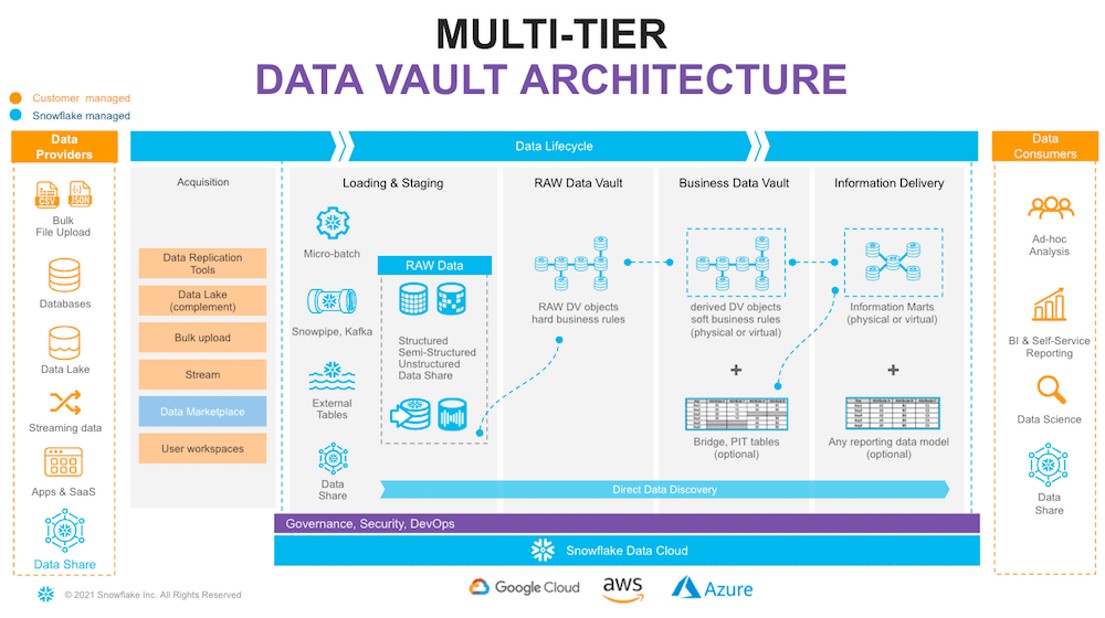
Prior to Snowflake, putting a view on top of a view resulted in a large degradation in performance. But because of the proprietary storage format in Snowflake, which is based on a “store-once-read-many” architecture, we can store the data one time while having multiple compute resources read from it. And when Snowflake is interacting with that data, there’s minimal to no performance degradation as you stack views on top of views. The result is a much faster pipeline as we can keep as many structures as possible virtual which has even led to a new pattern dubbed the “Virtual Vault”.
No More Rebuilding ETL Processes
Snowflake has completely transformed what was possible with modeling. You can now run your ETL process to your persistent stage, and once the information is there, everything in the data vault, business vault, and information marts can all be run as views. Instead of having to build an entire ETL process, you just write a simple script that contains the logic for your business rules. Once you’ve defined which business objects the information is related to, your team can give you feedback and tell you what KPIs matter to them, allowing for faster iterations and reduced time to market for delivering data to your internal customers.
Time Savings is Exponential
Traditionally, adding extra data sources and integrating that data was incredibly time-consuming.
While setting up Data Vault requires some extra time upfront, it pays off exponentially in the long term. Without Data Vault, adding a new data source can take up to six months, when building conformed dimensions with a large number of existing sources, because you need to change all the ETL processes and calculations by field. In many cases, adding a new data source to the Raw Vault can be done in one month, especially if the system has overlaps with business objects that have already been defined. Considering that an organization may be adding multiple data sources over time, the time savings is astounding.
Accelerate Data Vault Setup with AllCloud
AllCloud implements Data Vault on every data warehouse/lake project because it has so many advantages. Even if a customer decides to move to a different model moving forward, the persistent stage in Data Vault serves as an excellent foundation that supports switching to other models efficiently. And because AllCloud leverages accelerators to implement Data Vault faster, clients are able to get up and running as quickly as possible.
A recent example is a project we completed for a retail customer. We used our meta-programmed solution to quickly generate about 80% of the code needed to build their raw vault, which significantly sped up their implementation. With the Raw vault in place, the team was able to efficiently pair the client’s SKUs from one source with all of the data related to them in their other sources efficiently and enable unlocking insights previously unavailable.
AllCloud’s team of certified experts have extensive experience building Data Vaults and have pioneered improving commercial solutions and open source packages, such as dbt and dbt Vault respectively which allows customers to accelerate the programming of their Raw Data Vault. And with an industry-leading vendor ecosystem, we’re accelerating time-to-value even further. When you partner with AllCloud, you can get your people to the things they care about much faster, and enable viewing their data in ways previously unattainable.
Considering your approach to building a Data Vault? Contact our experts today!