Data has become a crucial part of every business. It flows in from all sides of an organization, whether it’s unstructured data from resources like IoT sensors, application logs, clickstreams, or structured data from transaction applications, relational databases, and spreadsheets.
This flow structure has resulted in a need to maintain a single source of truth and automate the entire pipeline–from data ingestion to transformation and analytic–> extract value from the data quickly.
There is a growing concern over the complexity of data analysis as the data volume, velocity, and variety increases. The concern stems from the number and complexity of steps it takes to get data to a state that is usable by business users. Often data engineering teams spend most of their time building and optimizing extract, transform, and load (ETL) pipelines. Automating the entire process can reduce the time to value and cost of operations. This post describes how to create a fully automated data cataloging and ETL pipeline to transform your data and explains how to build and automate a serverless data lake using AWS services.
This blog post is intended to review a step-by-step breakdown on how to build and automate a serverless data lake using AWS services. The post is based on my GitHub Repo that explains how to build serverless data lake on AWS. For more in depth information, you can review the project in the Repo.
Overview
When organizations build a serverless data lake, they usually start with Amazon S3 as the primary data store. Given the scalability and high availability of Amazon S3, it is best suited as the single source of truth for our data.
Various techniques can be used to ingest and store data in Amazon S3. For example, we can use Amazon Kinesis Data Firehose to ingest streaming data or AWS Database Migration Service (AWS DMS) to ingest relational data from existing databases. We can use AWS DataSync to ingest files from an on-premises Network File System (NFS). There are numerous possibilities.
Ingested data lands in Amazon S3 buckets that are referred to as ‘The Raw Zone’. To make that data available, we have to catalog its schema in the AWS Glue Data Catalog. We can do this using an AWS Lambda function invoked by an Amazon S3 trigger to start an AWS Glue crawler that catalogs the data. When the crawler is finished creating the table definition, we invoke a second Lambda function using an Amazon CloudWatch Events rule. This step starts an AWS Glue ETL job to process and output the data into another Amazon S3 bucket that we refer to as ‘the processed zone’.
The AWS Glue ETL job converts the data to Apache Parquet format and stores it in the processed S3 bucket. We can modify the ETL job to achieve other objectives, like more granular partitioning, compression, or enriching of the data. Monitoring and notification is an integral part of the automation process. As soon as the ETL job finishes, another CloudWatch rule sends us an email notification using an Amazon Simple Notification Service (Amazon SNS) topic. This notification indicates that our data was successfully processed.
But before we dive deep into the architecture, let’s see how AWS data & analytics landscape offers on AWS.
Ingest & Store
The first thing you have to do is get your data into S3. AWS offers a whole host of data ingestion tools to help you do that. You can use the Kinesis family of streaming data tools to ingest data that can be logged data streaming video data can be many different video types. You can use Kinesis analytics where you can analyze the data as it is streaming in and make decisions on that data before it even lands in the data lake.
Knowing that kind of real-time data path, Kinesis Analytics is actually an important part of streaming processing. If you think of an IoT use case where data lakes are used, think of a factory that monitors all the equipment and to make real-time decisions. For example, a Chip Fab might malfunction and there is a need to take action before it disrupts the entire log. Kinesis Analytics would be used to analyze that streaming log data that’s coming from the machinery read, and determine when the logs out of range data and flag it for action before anything fails.
An additional ingestion option, is that you might have a lot of traditional databases, either on-prem or in the cloud, that are relational data that you’re integrating into the data lake. To that end, AWS has Database migration services (DMS). This service allows for companies with On-prem equipment that doesn’t necessarily speak object storage or an analytics interface but is used to talking to a file device. Pharmaceutical companies are a good example for companies like these. You can use an AWS Storage Gateway to integrate that or an AWS Snowball to collect that data and ‘Lift & Shift’ it to the cloud.
Finally, if you may have an existing Hadoop cluster On-Prem or a data warehouse or even a large store device, you can set up AWS Direct Connect and start to set a direct network connection between your On-Prem environment in AWS services. This will make it look like one big hybrid system.
Data ingestion is key to making your data actionable, and you’ve got to pick the right tool for the right type of data.
Catalog & Search
The second part is building a searchable catalog. This element is fundamental for building a data lake that I would even go so far as saying that it’s not a data lake without it. Without that, what you have isn’t a data lake but rather a storage platform. If you’re going to take your data and get insights from it, you must know what it is you have. The Metadata associated with that data is ultimately how different datasets relate to each other.
That’s really where AWS Glue comes in. The product is a robust, flexible data catalog that builds as data comes into the Data Lake. It quickly crawls data to create a classified catalog and delivers insights upon it.
Once you’ve analyzed the data, you’ve got to be able to present it and derive insights. You can do that directly through analytic tools that Spark SQL natively, or decide to put up an API Gateway and set the structure up almost like a shopping cart for a data consumption model.
Using the AWS platform, you have a wide variety of tools like API Gateway, Cognito, AWS AppSync to help you build those user interfaces on top of your data lake.
Manage & Secure
Managing data security and governance is also a foundational aspect. A Data Lake wouldn’t be a usable data Lake if it weren’t secure. Ultimately a data lake is really about taking a bunch of individual silos of data, integrating those and getting greater insights that stem from getting a more complete view. If you have many silos, it may be easy to secure those individual silos to a certain number of users. On AWS, you have a wide variety of security services like Identity and Access Management(IAM), for example, that allow you to manage access to AWS services and resources securely. Using IAM, you can create and manage AWS users and groups, and use permissions to allow and deny their access to AWS resources.
Another example is the AWS Key Management Service (KMS), which allows you to create and manage cryptographic keys and control their use across a wide range of AWS services and applications.
Lastly, Amazon CloudWatch allows continuous monitoring of your AWS resources and applications, making it simple to assess, audit, and record resource configurations and changes. You can use a whole array of security and management tools to help you manage data in a very secure, robust, and granular fusion. Still, ultimately, a data lake is really about getting value out of your data.
Transform & Process
AWS gives you fast access and flexible serverless analytics using AWS Step Functions and AWS Lambda for orchestrating multiple ETL jobs involving a diverse set of technologies in an arbitrarily-complex ETL workflow.
AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume.
With Lambda, you can run code for virtually any type of application or back-end service, all with zero administration. Just upload your code, and Lambda takes care of everything required to run and scale your code with high availability.
You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.
AWS Step Functions is a web service that enables you to coordinate the components of distributed applications and microservices using visual workflows. You build applications from individual components. Each component performs a discrete function, or task, allowing you to scale and change applications quickly.
AWS gives you fast access and flexible analytic and processing tools to rapidly scale virtually any big data application, including data warehousing, clickstream analytics, fraud detection, recommendation engines, event-driven ETL, and serverless computing and IoT processing. You can use AWS Glue ETL that has two types of jobs: Python shell and Apache Spark. The Python shell job allows you to run small tasks utilizing a fraction of the computing resources and at a fraction of the cost. The Apache Spark job allows you to run medium- to large-sized tasks that are more compute- and memory-intensive by using a distributed processing framework.
Service like Amazon EMR, which offers you a Data Lake cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. You can use AWS Glue for that job processing.
Analytics & Serving
AWS offers native tools that allow you to query your data in place, such as:
Amazon Athena-The tool allows you an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL.
Redshift Spectrum – is a feature within AWS Redshift data warehousing service that allows Data Analysts to conduct fast, complex analysis on Amazon S3.
Amazon Sagemaker – is a tool that offers fully managed Machine Learning services that give every developer and data scientist the ability to build, train, and deploy machine learning (ML) models quickly.
And finally, AI Services as well as a whole host of third-party tools that are much more performance scalable for applications like SparkMlib for Data Warehousing.
The following diagram illustrates these areas and their related AWS services.
Data Lake on AWS
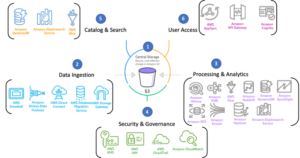
There are a number of common scenarios where the Analytics Lens applies, such as the following:
- Building a data lake as the foundation for your data and analytics initiatives
- Efficient batch data processing at scale
- Creating a platform for streaming ingest and real-time event processing
- Handling big data processing and streaming
- Data-preparation operations
This post shows you an example of how to build and automate the architecture below:
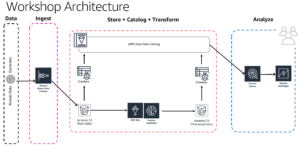
For more and full details please see my GitHub repo.
What you will learn from the workshop in the GitHub Repo:
- How to build a data processing pipeline and Data Lake using Amazon S3 for storing data
- Using Amazon Kinesis/MSK for real-time streaming data
- Using AWS Glue to automatically catalog datasets
- How to run interactive ETL scripts in an Amazon SageMaker Jupyter notebook connected to an AWS Glue development endpoint
- Run queries data using Amazon Athena & visualize it using Amazon QuickSight
Like I mentioned at the top, this post intended to review a step-by-step breakdown on how to build and automate a serverless data lake using AWS services. If you have any questions or need help with your Data Lake project, the Data team at AllCloud is here to help. If you decided to use the GitHub Repo I would love to hear your feedback.